Tu herramienta de Realidad Aumentada para la era del Spatial Computing
Ahorra recursos y semanas de desarrollo creando proyectos Web AR con nuestra reconocida tecnología
Regístrate gratisCasos de éxito
Descubre lo que nuestros clientes tienen que decir sobre la creación de experiencias de realidad aumentada con Onirix
- Durex
 VLMY&R
VLMY&R - Goiko Grill Now AR
- Santa Lucia Many Worlds
- Engen - Quickees Play MCI



Marcas que usan Onirix










Plantillas de experiencias
Ponemos a tu disposición una librería de experiencias con diferentes ejemplos y usos para que puedas inspirarte paso a paso creando de forma rápida.
-
Menú de restaurante en Web AR
Medio
-
Modelos 3D con texturas intercambiables
Básico
-
Juego de memoria brandeado para un envase de galletas
Avanzado
-
Binball : Gamificación con web AR para marcas
Avanzado
-
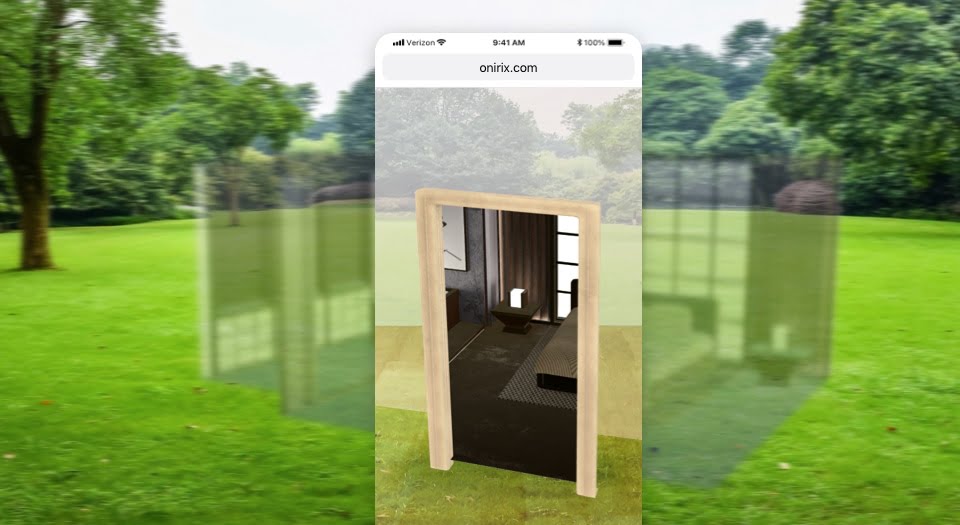
Planos de oclusión para Web AR – creando portales en RA
Básico
-
Puntos destacados en obras de arte con Web AR
Básico